Inzwischen gibt es auch das Video zur Podiumsdiskussion:
Am 3.05., 17:30, Stelle ich unser neues Projekt mit der Hans-Böckler-Stiftung auf der re:publica vor und diskutiere mit Matthias Spielkamp und Katharina Simbeck, moderiert von Melanie Stein. Hier geht es zum Programm.
Unter anderem zeige ich, wie man den Analysealgorithmus von IBM Watson austricksen kann.

Hier der Link zum Projekt: https://www.boeckler.de/11145.htm?projekt=S-2017-375-2%20B
Und hier die Struktur meines Inputreferats:
Zunächst sollte man sich dieses Video von IBM Watson ansehen:
Und hier gibt es die Daten: https://www.ibm.com/communities/analytics/watson-analytics-blog/hr-employee-attrition/
IBM Watson kommt zu dem Schluss, dass Überstunden (OverTime) der wichtigste Faktor sind, um vorherzusagen, ob jemand das Unternehmen verlässt.
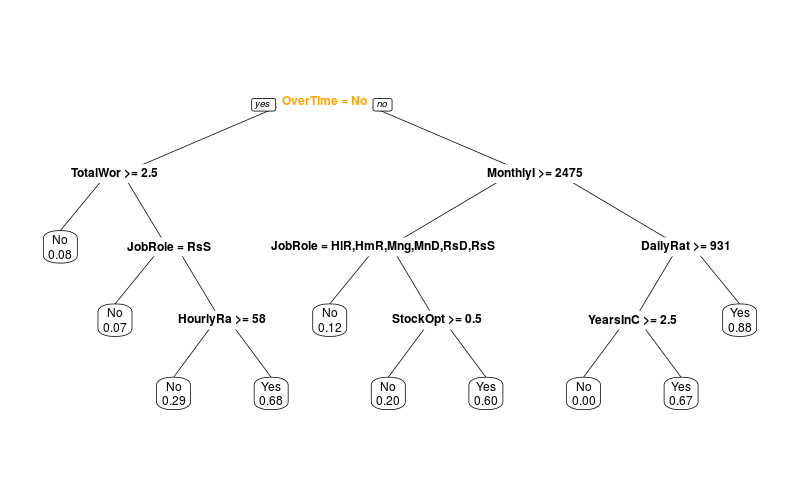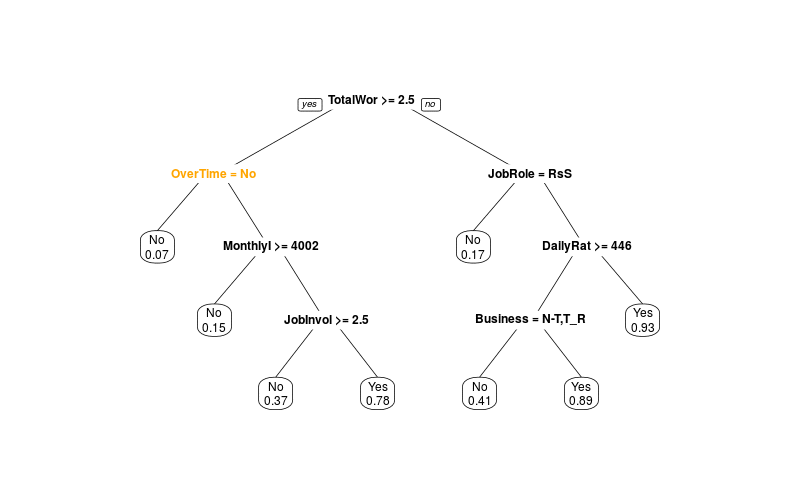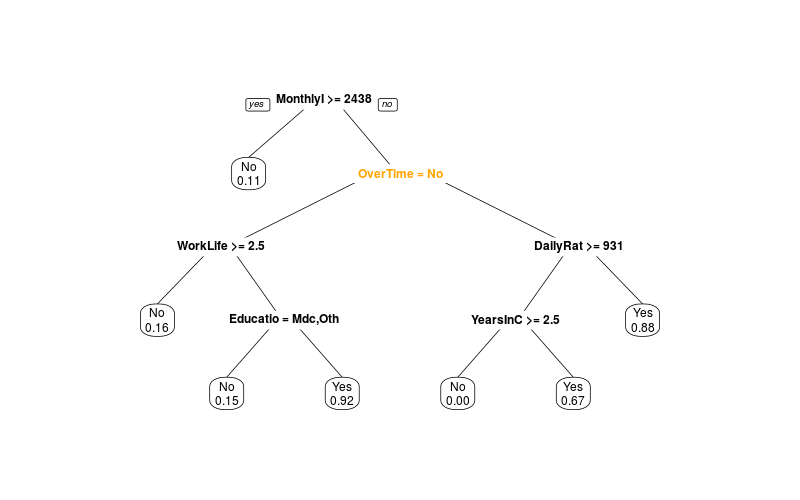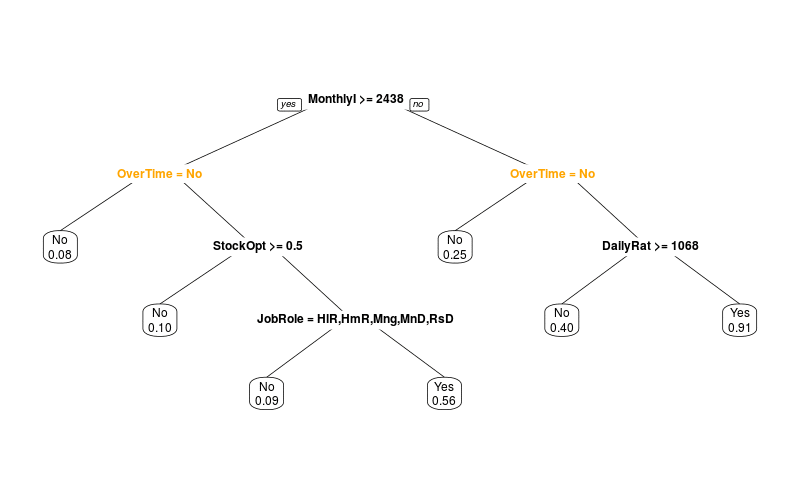
Ich habe versucht, den Decision Tree nachzubauen:
 Dann simuliere ich mit Jackknifing, was passiert, wenn nur ein Teil der Daten zur Verfügung steht:
Dann simuliere ich mit Jackknifing, was passiert, wenn nur ein Teil der Daten zur Verfügung steht:
 Man sieht also, dass man nicht einfach die erste Variable als wichtigste nehmen kann. Decision Trees sind nicht besonders robust, weil sie "gierig" sind: Sie nehmen immer die Unterteilung, die gerade am meisten bringt, ohne zu berechnen, welche Auswirkungen das für die nächsten Splits hat.
Man sieht also, dass man nicht einfach die erste Variable als wichtigste nehmen kann. Decision Trees sind nicht besonders robust, weil sie "gierig" sind: Sie nehmen immer die Unterteilung, die gerade am meisten bringt, ohne zu berechnen, welche Auswirkungen das für die nächsten Splits hat.
Hätte man viele simulierte Decision Trees kombiniert (Random Forest), wäre das Ergebnis übrigens ganz anders:
 Anstelle von OverTime zeigt sich, dass das monatliche Einkommen viel entscheidender ist. Wenn die Personalabteilung also will, dass die Leute im Unternehmen bleiben, sollte sie höhere Löhne zahlen!
Anstelle von OverTime zeigt sich, dass das monatliche Einkommen viel entscheidender ist. Wenn die Personalabteilung also will, dass die Leute im Unternehmen bleiben, sollte sie höhere Löhne zahlen!
Abschließend kann man noch simulieren, wie Anfällig der Algorithmus ist, wenn nur einzelne Datenpunkte verändert werden:
 Fazit: Wenn immer mehr Entscheidungen über Algorithmen getroffen werden, dann bedeutet das Wissen über diese Verfahren und der Zugang zu den Daten auch Macht. Diese Macht wird nicht von den Unternehmern (re)produziert, sondern von den Arbeitnehmern. Daher: Alle Flip-Flops stehen still, wenn dein schlauer Kopf es will!
Fazit: Wenn immer mehr Entscheidungen über Algorithmen getroffen werden, dann bedeutet das Wissen über diese Verfahren und der Zugang zu den Daten auch Macht. Diese Macht wird nicht von den Unternehmern (re)produziert, sondern von den Arbeitnehmern. Daher: Alle Flip-Flops stehen still, wenn dein schlauer Kopf es will!
Am 3.05., 17:30, Stelle ich unser neues Projekt mit der Hans-Böckler-Stiftung auf der re:publica vor und diskutiere mit Matthias Spielkamp und Katharina Simbeck, moderiert von Melanie Stein. Hier geht es zum Programm.
Unter anderem zeige ich, wie man den Analysealgorithmus von IBM Watson austricksen kann.

Hier der Link zum Projekt: https://www.boeckler.de/11145.htm?projekt=S-2017-375-2%20B
Und hier die Struktur meines Inputreferats:
Zunächst sollte man sich dieses Video von IBM Watson ansehen:
Und hier gibt es die Daten: https://www.ibm.com/communities/analytics/watson-analytics-blog/hr-employee-attrition/
IBM Watson kommt zu dem Schluss, dass Überstunden (OverTime) der wichtigste Faktor sind, um vorherzusagen, ob jemand das Unternehmen verlässt.
Ich habe versucht, den Decision Tree nachzubauen:

Hätte man viele simulierte Decision Trees kombiniert (Random Forest), wäre das Ergebnis übrigens ganz anders:

Abschließend kann man noch simulieren, wie Anfällig der Algorithmus ist, wenn nur einzelne Datenpunkte verändert werden:
