Im Iran finden
derzeit Proteste gegen die Regierung statt. Im Zuge des so genannten
„Arabischen Frühlings“ spielte Twitter eine nicht unwesentliche
Rolle. Schon bei den Protesten 2009 gab es Berichte über den Einsatz
von Social Bots, also automatisierten Fake-Accounts. Es liegt daher
auf der Hand, zu fragen, ob sich derzeit Social Bots in die
Meinungsbildung zum Thema Iran einmischen und wenn ja, ob sich ein
Effekt auf den Diskurs nachweisen lässt. Im Folgenden wird anhand
eines Samples von ca. 1.000.000 Tweets zum Thema „Iran“
nachgewiesen, dass Accounts aktiv sind, die mit hoher
Wahrscheinlichkeit als Social Bots eingestuft werden müssen. Darüber
hinaus wird mit Textmining-Methoden gezeigt, dass diese Social Bots
zu einer negativen Stimmung (gemessen als Sentiment) in der Debatte
beitragen. Damit wird ein
nachweisbarer Effekt des Einsatzes von Social Bots in politischen
Debatten aufgezeigt.
Datengrundlage
Die Daten wurden
generiert, indem über die Streaming-API von Twitter in einem
Zeitraum von 24 Stunden vom 30.12.2017 bis zum 31.12.2017 nach dem
Wort „Iran“ gesucht wurde. Dabei wurden 899.745 Tweets mit
Metadaten gespeichert.
Methode
Boterkennung
Die Existenz von
Social Bots ist unstrittig, da es diverse Programme zur automatischen
Steuerung von Fake-Accounts gibt und diese Programme auch eingesetzt
werden und weil die Plattformbetreiber – wie Twitter – selbst
angeben, gegen Social Bots vorzugehen.
Der Begriff des
Social Bot ist aber unzureichend definiert. Unter Social Bots werden
automatisierte Accounts verstanden, die vorgeben echte Nutzer zu
sein. Es ist aber unklar, ab wann ein Account als automatisiert gilt.
Teilweise werden „handgefertigte“ Inhalte einfach automatisch
gepostet (über die Twitter API). Gleichzeitig kann auch ganz ohne
eine Software ein hoher Grad an Automatisierung erreicht werden, zum
Beispiel wenn Gruppen von Nutzern durch Copy&Paste sehr schnell
große Mengen an Posts erzeugen. Auch die „Täuschungsabsicht“
ist nicht eindeutig, da die Motive der Nutzer unbekannt sind. In der
Praxis ist es daher nahezu unmöglich, einen Account unzweifelhaft
als Social Bot zu erkennen.
In der Forschung zu
Social Bots haben sich zwei unterschiedliche Methoden herausgebildet:
Machine Learning und Heuristiken. Beim Machine Learning wird – in
der Regel auf Basis eines handcodierten Datensatzes – automatisch
nach Mustern gesucht, anhand derer Social Bots durch einen Computer
erkannt werden können. Die Schwierigkeit hierbei besteht darin, dass
ein solches System nur Bots finden wird, die ähnlich sind zu den
Daten, auf denen das System trainiert wurde. Der Heuristik-Ansatz
arbeitet mit theoretisch hergeleiteten Regeln, die echte
Twitternutzung von Social Bots unterscheiden sollen. Der Nachteil bei
diesem Ansatz ist, dass die Regeln starr sind: Das System kann sich
nicht durch neue Daten verbessern. Zudem ist es sehr schwierig
einzuschätzen, welche Regel wie gut funktioniert und wie die
Kombination von Regeln zu bewerten ist.
Für die folgende
Untersuchung wurde ein Heuristik-Ansatz gewählt, da keine
Trainingsdaten vorliegen, die auf den Fall Iran passen. Denn erstens
können sich Social Bots sehr schnell verändern, indem ihre
Steuerung angepasst wird. Es ist daher immer fraglich, ob historische
Daten zur Klassifizierung aktueller Ereignisse genommen werden
können. Zweitens ist das Verhalten von Twitternutzern sehr stark vom
jeweiligen Kontext abhängig. In einem Diskurs zu den aktuellen
Protesten im Iran werden sich die Nutzer vermutlich anders verhalten
als in einem Diskurs zu einer Wahl, der sich über mehrere Wochen
erstreckt. Auch hier stellt sich daher die Frage, ob Daten, die in
einem anderen Kontext erhoben wurden, als Trainingsdaten verwendet
werden können.
Im Folgenden wird
mit vier unterschiedlichen Heuristiken gearbeitet: Analyse der Quelle
(source), Verhältnis Freunde zu Followern, Anzahl der Tweets pro Tag
und Textduplicate.
Wenn ein Tweet nicht
über die Twitter-App gesendet wird, sondern über ein anderes
Programm, dass sich der API bedient, dann wird dies in den Metadaten
vermerkt (sofern dieser Vermerk nicht manipuliert wird). Eine Analyse
dieser source Variable in
den Iran-Daten hat 97
„verdächtige“ Quellen ergeben. Dabei handelt es sich zum Teil um
bekannte Dienste zur Automatisierung (wie IFTTT), die allerdings auch
von seriösen Accounts benutzt werden, zum Teil um Social Bot
Software (wie twittbot). Es tauchen aber auch einige obskure Quellen
auf wie www.AgendaOfEvil.com, pipes.cyberguerrilla.org und
www.rightstreem.com. Daneben gibt es eine Reihe von alternativen
Twitterapps und Medienseiten, bei denen nicht klar ist, ob sie zur
Betreibung von Social Bots genutzt werden können. Insgesamt wurden
24.718 Tweets im Sample von diesen sources gesendet.
Das Verhältnis von Freunden und Followern ist auch sehr interessant. Früher war es so, dass Bots viele Freunde hatten (vielen Nutzern folgten), aber selbst wenig Follower hatten. Unsere Untersuchungen haben gezeigt, dass das Verhältnis heute bei Bots häufig ausgeglichen ist, weil die Bot-Software nur weiteren Nutzern folgt, wenn es auch neue Freunde gibt. Häufig folgen sich Bots auch einfach gegenseitig. Man kann also nach Nutzern Ausschau halten, deren Friend/Follower Ratio in etwa 1 ist. Da Accounts mit sehr wenigen Freunden und Followern zufällig eine solche Ratio aufweisen können, wurden nur Accounts mit mehr als 100 Followern einbezogen. Auf diese Weise wurden 58.372 Tweets identifiziert.
Die durchschnittliche Anzahl der Tweets, die ein Nutzer pro Tag twittert, wird ebenfalls häufig als Kriterium für Social Bots herangezogen. Die Idee dabei ist, dass Bots sich durch besonders starke Aktivitäten auszeichnen. Eine Frage ist allerdings, ab wie vielen Tweets ein Nutzer „auffällig“ ist. Das Oxford-Internet Institut verwendet einfach den kritischen Wert 50 Tweets pro Tag. Weniger beliebig wird die Heuristik wenn der kritische Wert berechnet wird. Dafür eigenen sich zwei unterschiedliche Ansätze. Man kann die Interquartile-Range berechnen (also den Abstand des oberen Viertels vom Median) und diesen Wert dann mit 1,5 multiplizieren. Dieses Maß ist ein klassisches Outliermaß in der Statistik. Alle Werte, die größer sind als das Anderthalbfache der IQR sind unverhältnismäßig weit vom Median entfernt. Im vorliegenden Sample wären dass alle Nutzer, die mehr als 54 Mal am Tag twittern. Noch konservativer ist es, die 5% der aktivsten Twittere als auffällig zu nehmen. Dieser Ansatz wurde hier verfolgt. Nutzer, die im Durchschnitt mehr als 165 Mal am Tag getwittert haben, wurden als Bot-verdächtig eingestuft.
Wenn Texte automatisch generiert (oder massenhaft verbreitet werden) kann es sein, dass identische Texte auftauchen. Twitter hat für das Teilen von Texten eigentlich die Retweet-Funktion. Wenn Texte identisch sind, ohne dass es sich um Retweets handelt, kann das ein Hinweis auf Automatisierung sein. Im vorliegenden Sample war das allerdings nur bei 820 Tweets der Fall.
Bei unterschiedlichen Heuristiken stellt sich die Frage, wie das Verhältnis der Regeln zueinander ist. Müssen alle Regeln in jedem Fall erfüllt sein, oder reicht es, wenn irgendeine Regel greift? Da Social Bots sehr unterschiedlich sein können, würde einiges an Genauigkeit verloren gehen, wenn nur nach den Fällen geschaut würde, in denen alle Regeln erfüllt sind. Wenn aber jede Regel für sich ausreicht, dann ist zum Beispiel klar, dass die 5% der aktivsten Nutzer automatisch als Bots eingestuft werden. Im Folgenden wurden zwei unterschiedliche Ansätze verfolgt: Erstens wurden alle Tweets, bei denen eine der Regeln gegriffen hat als verdächtig (suspicious) eingestuft. Zweitens wurden alle Tweets, bei denen mindestens zwei Heuristiken zutrafen, als Bots eingestuft.
Gerade Medienaccounts twittern häufig sehr viel und könnten so als Bots eingestuft werden (zumal sie auch meist automatisiert agieren). Meistens sind diese Accounts aber von Twitter verifiziert. Durch das Kriterium verified hat man also eine negative Heuristik, die Social Bots ausschließt.
Die Kombination dieser Heuristiken lieferte 118.071 suspicious Tweets und 10.126 Bot-Tweets.
Textmining
Um die Texte zu analysieren wurde zunächst ein bag-of-words-Ansatz gewählt. Dabei wird gezählt, welche Worte wie häufig in welchen Tweets vorkommen. Die Ergebnisse werden in Wordclouds präsentiert, bei denen für die Nicht-Bots, die Verdächtigen und die Bots die häufigsten Worte dargestellt werden (wobei die Größe der relativen Häufigkeit entspricht). Worte, die in sehr vielen Dokumenten vorkommen, sind häufig weniger aussagekräftig. Umgekehrt sind die Worte, die in einem Dokument besonders häufig sind, oft besonders wichtig für die Einschätzung. Anstelle der einfachen Häufigkeit verwendet man daher die term frequency–inverse document frequency (TFIDF).
In einem zweiten Schritt wurde untersucht, welche Worte häufig mit welchen anderen Worten gemeinsam auftauchen (co-occurence). Für die drei Gruppen wurden dann Graphen erstellt, die jeweils die 20 häufigsten Worte mit bis zu fünf Worten aus ihrem direktem Umfeld darstellen. Dadurch lässt sich sehen, ob dieselben Worte eventuell in einem unterschiedlichen Kontext benutzt worden ist.
Darüber hinaus wurde eine Sentiment-Analyse durchgeführt. Dafür werden die Worte mit einem Lexikon verglichen, dass für (nahezu) jedes (englische) Wort einen Wert ermittelt, wie positiv oder negativ das Wort verwendet wird. Ist die Summe dieser Werte für einen Text negativ, spricht man von einem negativen Sentiment.
Abschließend wurde untersucht, ob die Unterschiede, die sich bei der Sentiment-Analyse ergeben haben, zufällig sind oder nicht. Dazu wurde das Sentiment der Worte in den Gruppen Nicht-Bot, Verdächtig und Bot mit einem Kolgomorov-Smirnov-Test überprüft. Die Null-Hypothese ist dabei, dass die Daten aus der gleichen Verteilungsfunktion stammen. Der p-Wert zeigt, mit welcher Wahrscheinlichkeit die Null-Hypothese anzunehmen ist.
Ergebnisse
Die folgende Tabelle zeigt die 20 aktivsten Nutzer, die als Bots eingestuft wurden. Es wird deutlich, dass es sich definitiv um sehr aktive Accounts handelt, die sich stark von „normalen“ Nutzern unterscheiden.
| screen_name | TpD | follower | friends | Source |
| Davewellwisher | 1082.13116726835 | 27374 | 15854 | <a href="https://ifttt.com" rel="nofollow">IFTTT</a> |
| TinaOrt79591465 | 291.44246031746 | 7492 | 7841 | <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a> |
| americanshomer | 310.317204301075 | 5636 | 5669 | <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a> |
| BetigulCeylan | 230.866009042335 | 2394 | 2277 | <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a> |
| zyiteblog | 632.971712538226 | 1688 | 3687 | <a href="http://www.hootsuite.com" rel="nofollow">Hootsuite</a> |
| ErengwaM | 268.792144026187 | 1177 | 1200 | <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a> |
| PeggyRuppe | 229.74679943101 | 6424 | 6347 | <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a> |
| sturm_tracey | 234.446078431373 | 2058 | 2105 | <a href="https://mobile.twitter.com" rel="nofollow">Twitter Lite</a> |
| CityofInvestmnt | 96.8357142857143 | 5180 | 5017 | <a href="https://ifttt.com" rel="nofollow">IFTTT</a> |
| emet_news_press | 519.184782608696 | 14137 | 3304 | <a href="http://www.hootsuite.com" rel="nofollow">Hootsuite</a> |
| favoriteauntssi | 476.096153846154 | 5045 | 5166 | <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a> |
| Sakpol_SE | 442.321109123435 | 4605 | 0 | <a href="https://sakpol.se" rel="nofollow">Sakpol Magic</a> |
| dreamedofdust | 626.168421052632 | 2640 | 84 | <a href="https://ifttt.com" rel="nofollow">IFTTT</a> |
| NarrendraM | 2034.36666666667 | 1952 | 251 | <a href="https://ifttt.com" rel="nofollow">IFTTT</a> |
| YMcglaun | 206.769795918367 | 10571 | 10559 | <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a> |
| lynn_weiser | 405.789724072312 | 20009 | 19756 | <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a> |
| AngelaKorras | 194.026874585269 | 3666 | 3768 | <a href="http://www.echofon.com/" rel="nofollow">Echofon</a> |
| MarjanFa1 | 261.758865248227 | 6183 | 6059 | <a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a> |
| RichGossger | 355.432432432432 | 587 | 571 | <a href="http://twitter.com" rel="nofollow">Twitter Web Client</a> |
| sness5561_ness | 451.463414634146 | 11994 | 12477 | <a href="http://twitter.com/download/iphone" rel="nofollow">Twitter for iPhone</a> |
Der Nutzer Sakpol_SE ist zwar ein Bot, sagt das aber auch in seiner Beschreibung und würde somit nicht als Social Bot zählen.
Die folgende Abbildung zeigt die Wordclouds für Nicht-Bots, Verdächtige und Bots:
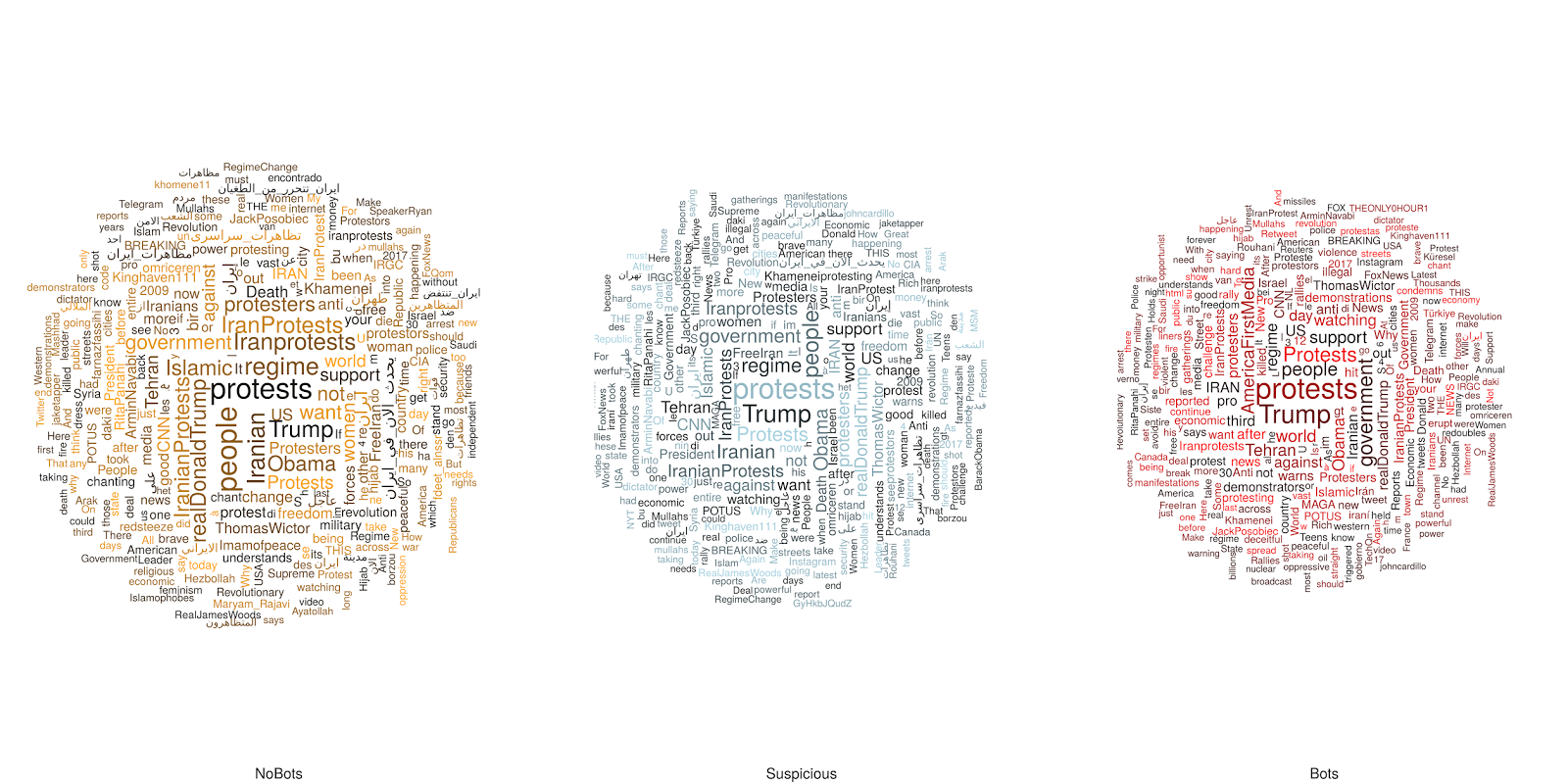 |
| Wordclouds |
Besonders viel sticht hier erstmal nicht ins Auge. Zwar ist Trump bei den Bots stärker vertreten, die benutzten Worte scheinen sich allerdings nicht stark zu unterscheiden.
Die Co-occurence zeigt erste Unterschiede aber auch viele Ähnlichkeiten, was die folgenden Abbildungen verdeutlichen:



In allen drei Abbildungen findet sich der Zusammenhang von Obama mit Hezbollah. In dem Graph, der sich auf die Bots beschränkt, werden stärker Ökonomische Themen angesprochen und Trump nimmt einen größeren Stellenwert ein. Zudem taucht auch der Hashtag MAGA auf. Das Thema der Frauenrechte kommt nur in den Nicht-Bot-Daten vor. Insgesamt muss aber festgestellt werden, dass die Bots offenbar zu sehr ähnlichen Themen posten und sich daher die inhaltliche Darstellung der Proteste kaum ändert.
Anders sieht es aber aus, wenn man eine Sentiment-Analyse anschließt. Hier zeigt sich, dass die Bots mehr negative Worte verwenden, als die anderen Nutzer. Für die Nicht-Bots ergibt sich ein durchschnittliches Sentiment von -0,049, für die Suspicious-Gruppe -0,063 und für die Bots -0.094. Der KS-Test zwischen Nicht-Bots und Suspicious ergibt einen Wert von 0,042 mit einem p-Wert gegen Null. KS-Test zwischen Nicht-Bots und Bots fällt sogar noch deutlicher aus, mit einem Wert von 0,12 und ebenfalls einem p-Wert von Null. Es ist also sehr unwahrscheinlich, dass die Worte (und ihre positiven und negativen Werte) aus derselben Verteilung stammen.
Diese Unterschiede lassen sich auch visualisieren, indem man die empirische kumulative Dichtefunktion betrachtet.

Man sieht, dass die Dichtefunktion der Bots im negativen Bereich deutlich stärker ausgeprägt ist.
Fazit
Hier liegt ein empirisch überprüfbarer Befund vor, der zeigt, dass Social Bots die Stimmung in politischen Debatten verändern können. Geht man davon aus, dass Debatten auf Twitter einen politischen Effekt haben und das Stimmungen in Sozialen Netzwerken eine große Bedeutung zukommt, dann muss man folgern, dass Social Bots einen politischen Einfluss haben, zumindest im untersuchten Fall.
Zu bedenken ist allerdings, dass gerade im Bereich des Textmining sehr viele implizite methodische Entscheidungen getroffen werden (was zum Beispiel das Säubern der Texte anbelangt), die eventuell Einfluss auf die Ergebnisse haben können. Um die hier präsentierten Ergebnisse überprüfbar zu machen, werden daher im Folgenden die verwendeten Programmcodes aufgeführt.
Simon Hegelich, 01.01.2018
R-Codes
Functions
First some functions, I have used in the
code. The formatTwitterDate Function was taken from https://rdrr.io/github/SMAPPNYU/smappR/man/format.twitter.date.html. Multiplot comes from http://www.cookbook-r.com/Graphs/Multiple_graphs_on_one_page_(ggplot2)/. Some very good ideas were taken from https://rpubs.com/imtiazbdsrpubs/230280.
###
IranBot Functions
### URL parts
URL_parts <- function(x) {
m <- regexec("^(([^:]+)://)?([^:/]+)(:([0-9]+))?(/.*)", x)
parts <- do.call(rbind,
lapply(regmatches(x, m), `[`, c(3L, 4L, 6L, 7L)))
colnames(parts) <- c("protocol","host","port","path")
parts
}
### Format Twitter date
formatTwDate <- function(datestring, format="datetime"){
if (format=="datetime"){
date <- as.POSIXct(datestring, format="%a %b %d %H:%M:%S %z %Y")
}
if (format=="date"){
date <- as.Date(datestring, format="%a %b %d %H:%M:%S %z %Y")
}
return(date)
}
# Multiple plot function
#
# ggplot objects can be passed in ..., or to plotlist (as a list of ggplot objects)
# - cols: Number of columns in layout
# - layout: A matrix specifying the layout. If present, 'cols' is ignored.
#
# If the layout is something like matrix(c(1,2,3,3), nrow=2, byrow=TRUE),
# then plot 1 will go in the upper left, 2 will go in the upper right, and
# 3 will go all the way across the bottom.
#
multiplot <- function(..., plotlist=NULL, file, cols=1, layout=NULL) {
library(grid)
# Make a list from the ... arguments and plotlist
plots <- c(list(...), plotlist)
numPlots = length(plots)
# If layout is NULL, then use 'cols' to determine layout
if (is.null(layout)) {
# Make the panel
# ncol: Number of columns of plots
# nrow: Number of rows needed, calculated from # of cols
layout <- matrix(seq(1, cols * ceiling(numPlots/cols)),
ncol = cols, nrow = ceiling(numPlots/cols))
}
if (numPlots==1) {
print(plots[[1]])
} else {
# Set up the page
grid.newpage()
pushViewport(viewport(layout = grid.layout(nrow(layout), ncol(layout))))
# Make each plot, in the correct location
for (i in 1:numPlots) {
# Get the i,j matrix positions of the regions that contain this subplot
matchidx <- as.data.frame(which(layout == i, arr.ind = TRUE))
print(plots[[i]], vp = viewport(layout.pos.row = matchidx$row,
layout.pos.col = matchidx$col))
}
}
}
distill.cog = function(mat1, # input TCM ADJ MAT
title, # title for the graph
s, # no. of central nodes
k1, # max no. of connections
color){
library(igraph)
a = colSums(mat1) # collect colsums into a vector obj a
b = order(-a) # nice syntax for ordering vector in decr order
mat2 = mat1[b, b] # order both rows and columns along vector b
diag(mat2) = 0
## +++ go row by row and find top k adjacencies +++ ##
wc = NULL
for (i1 in 1:s){
thresh1 = mat2[i1,][order(-mat2[i1, ])[k1]]
mat2[i1, mat2[i1,] < thresh1] = 0 # neat. didn't need 2 use () in the subset here.
mat2[i1, mat2[i1,] > 0 ] = 1
word = names(mat2[i1, mat2[i1,] > 0])
mat2[(i1+1):nrow(mat2), match(word,colnames(mat2))] = 0
wc = c(wc,word)
} # i1 loop ends
mat3 = mat2[match(wc, colnames(mat2)), match(wc, colnames(mat2))]
ord = colnames(mat2)[which(!is.na(match(colnames(mat2), colnames(mat3))))] # removed any NAs from the list
mat4 = mat3[match(ord, colnames(mat3)), match(ord, colnames(mat3))]
graph <- graph.adjacency(mat4, mode = "undirected", weighted=T) # Create Network object
graph = simplify(graph)
V(graph)$color[1:s] = color[1]
V(graph)$color[(s+1):length(V(graph))] = color[2]
graph = delete.vertices(graph, V(graph)[ degree(graph) == 0 ]) # delete singletons?
plot(graph,
layout = layout.fruchterman.reingold,
main = title)
} # func ends
text.clean = function(x) # text data
{ require("tm")
x = gsub("<.*?>", " ", x) # regex for removing HTML tags
x = iconv(x, "latin1", "ASCII", sub="") # Keep only ASCII characters
x = gsub("[^[:alnum:]]", " ", x) # keep only alpha numeric
x = tolower(x) # convert to lower case characters
x = removeNumbers(x) # removing numbers
x = stripWhitespace(x) # removing white space
x = gsub("^\\s+|\\s+$", "", x) # remove leading and trailing white space
return(x)
}
DataBuilder
### URL parts
URL_parts <- function(x) {
m <- regexec("^(([^:]+)://)?([^:/]+)(:([0-9]+))?(/.*)", x)
parts <- do.call(rbind,
lapply(regmatches(x, m), `[`, c(3L, 4L, 6L, 7L)))
colnames(parts) <- c("protocol","host","port","path")
parts
}
### Format Twitter date
formatTwDate <- function(datestring, format="datetime"){
if (format=="datetime"){
date <- as.POSIXct(datestring, format="%a %b %d %H:%M:%S %z %Y")
}
if (format=="date"){
date <- as.Date(datestring, format="%a %b %d %H:%M:%S %z %Y")
}
return(date)
}
# Multiple plot function
#
# ggplot objects can be passed in ..., or to plotlist (as a list of ggplot objects)
# - cols: Number of columns in layout
# - layout: A matrix specifying the layout. If present, 'cols' is ignored.
#
# If the layout is something like matrix(c(1,2,3,3), nrow=2, byrow=TRUE),
# then plot 1 will go in the upper left, 2 will go in the upper right, and
# 3 will go all the way across the bottom.
#
multiplot <- function(..., plotlist=NULL, file, cols=1, layout=NULL) {
library(grid)
# Make a list from the ... arguments and plotlist
plots <- c(list(...), plotlist)
numPlots = length(plots)
# If layout is NULL, then use 'cols' to determine layout
if (is.null(layout)) {
# Make the panel
# ncol: Number of columns of plots
# nrow: Number of rows needed, calculated from # of cols
layout <- matrix(seq(1, cols * ceiling(numPlots/cols)),
ncol = cols, nrow = ceiling(numPlots/cols))
}
if (numPlots==1) {
print(plots[[1]])
} else {
# Set up the page
grid.newpage()
pushViewport(viewport(layout = grid.layout(nrow(layout), ncol(layout))))
# Make each plot, in the correct location
for (i in 1:numPlots) {
# Get the i,j matrix positions of the regions that contain this subplot
matchidx <- as.data.frame(which(layout == i, arr.ind = TRUE))
print(plots[[i]], vp = viewport(layout.pos.row = matchidx$row,
layout.pos.col = matchidx$col))
}
}
}
distill.cog = function(mat1, # input TCM ADJ MAT
title, # title for the graph
s, # no. of central nodes
k1, # max no. of connections
color){
library(igraph)
a = colSums(mat1) # collect colsums into a vector obj a
b = order(-a) # nice syntax for ordering vector in decr order
mat2 = mat1[b, b] # order both rows and columns along vector b
diag(mat2) = 0
## +++ go row by row and find top k adjacencies +++ ##
wc = NULL
for (i1 in 1:s){
thresh1 = mat2[i1,][order(-mat2[i1, ])[k1]]
mat2[i1, mat2[i1,] < thresh1] = 0 # neat. didn't need 2 use () in the subset here.
mat2[i1, mat2[i1,] > 0 ] = 1
word = names(mat2[i1, mat2[i1,] > 0])
mat2[(i1+1):nrow(mat2), match(word,colnames(mat2))] = 0
wc = c(wc,word)
} # i1 loop ends
mat3 = mat2[match(wc, colnames(mat2)), match(wc, colnames(mat2))]
ord = colnames(mat2)[which(!is.na(match(colnames(mat2), colnames(mat3))))] # removed any NAs from the list
mat4 = mat3[match(ord, colnames(mat3)), match(ord, colnames(mat3))]
graph <- graph.adjacency(mat4, mode = "undirected", weighted=T) # Create Network object
graph = simplify(graph)
V(graph)$color[1:s] = color[1]
V(graph)$color[(s+1):length(V(graph))] = color[2]
graph = delete.vertices(graph, V(graph)[ degree(graph) == 0 ]) # delete singletons?
plot(graph,
layout = layout.fruchterman.reingold,
main = title)
} # func ends
text.clean = function(x) # text data
{ require("tm")
x = gsub("<.*?>", " ", x) # regex for removing HTML tags
x = iconv(x, "latin1", "ASCII", sub="") # Keep only ASCII characters
x = gsub("[^[:alnum:]]", " ", x) # keep only alpha numeric
x = tolower(x) # convert to lower case characters
x = removeNumbers(x) # removing numbers
x = stripWhitespace(x) # removing white space
x = gsub("^\\s+|\\s+$", "", x) # remove leading and trailing white space
return(x)
}
DataBuilder
###
Databuilder Iran BotAnalyse
# load packages
library(streamR)
library(ROAuth)
library(twitteR)
# authenticate Twitter API
requestURL <- "https://api.twitter.com/oauth/request_token"
accessURL <- "https://api.twitter.com/oauth/access_token"
authURL <- "https://api.twitter.com/oauth/authorize"
consumerKey <- "xxxxxyyyyyzzzzzz"
consumerSecret <- "xxxxxxyyyyyzzzzzzz111111222222"
token = "xxxxxyyyyyyyyyyyzzzzzzzzz"
tokenSecret = "xxxxxxxxxxxxxyyyyyyyyyyyzzzzzzzzz"
# get 24 hours of "Iran" from STREAMING-API
for(i in 1:24){
file = paste0("tweets", gsub(" |:", "-", Sys.time()), ".json")
track = "Iran"
follow = NULL
loc = NULL #c(50.33, 6.1, 52.36, 9.4)
lang = NULL
time = 60*60
tweets = NULL
filterStream(file.name = file, track = track,
follow = follow, locations = loc, language = lang,
timeout = time, tweets = tweets, oauth = Cred,
verbose = TRUE)
}
fl <- list.files()[grepl("tweets2017", list.files())]
df <- parseTweets(fl[1], verbose = FALSE)
for(i in 2:length(fl)){
df2 <- parseTweets(fl[i], verbose = FALSE)
df <- rbind(df, df2)
rm(list="df2")
}
saveRDS(df, "iranDF.rds")
gc()
}
# load packages
library(streamR)
library(ROAuth)
library(twitteR)
# authenticate Twitter API
requestURL <- "https://api.twitter.com/oauth/request_token"
accessURL <- "https://api.twitter.com/oauth/access_token"
authURL <- "https://api.twitter.com/oauth/authorize"
consumerKey <- "xxxxxyyyyyzzzzzz"
consumerSecret <- "xxxxxxyyyyyzzzzzzz111111222222"
token = "xxxxxyyyyyyyyyyyzzzzzzzzz"
tokenSecret = "xxxxxxxxxxxxxyyyyyyyyyyyzzzzzzzzz"
# get 24 hours of "Iran" from STREAMING-API
for(i in 1:24){
file = paste0("tweets", gsub(" |:", "-", Sys.time()), ".json")
track = "Iran"
follow = NULL
loc = NULL #c(50.33, 6.1, 52.36, 9.4)
lang = NULL
time = 60*60
tweets = NULL
filterStream(file.name = file, track = track,
follow = follow, locations = loc, language = lang,
timeout = time, tweets = tweets, oauth = Cred,
verbose = TRUE)
}
fl <- list.files()[grepl("tweets2017", list.files())]
df <- parseTweets(fl[1], verbose = FALSE)
for(i in 2:length(fl)){
df2 <- parseTweets(fl[i], verbose = FALSE)
df <- rbind(df, df2)
rm(list="df2")
}
saveRDS(df, "iranDF.rds")
gc()
}
Maincode
library(data.table)
library(tm)
library(SnowballC)
library(wordcloud)
library(RColorBrewer)
library(text2vec)
library(stringr)
library(RWeka)
library(tokenizers)
library(slam)
library(ggplot2)
library(igraph)
library(textir)
library(qdap)
df <- readRDS("iranDF.rds")
setDT(df)
class(df)
sources <- df[, URL_parts(source)[,2]]
sort(table(sources)[table(sources)>10], decreasing = T)
# Sources other than twitter.com are suspicious
#collect suspicious sources
auto <- c("publicize.wp.com", "www.echofon.com", "www.hootsuite.com", "tapbots.com",
"www.tweetcaster.com", "www.crowdfireapp.com", "ifttt.com", "twittbot.net", "software.complete.org",
"twicca.r246.jp", "roundteam.co", "twibble.io", "paper.li", "twitterrific.com", "mvilla.it",
"dlvrit.com", "bufferapp.com", "www.lost-property.eu", "www.newsdingo.com",
"www.news365247live.com", "corebird.baedert.org", "earthobservatory.ch",
"www.besoyepirozi.com","nosudo.co", "www.twitpane.com", "www.twhirl.org",
"www.handmark.com", "www.bennedemisim.com", "trendinalia.com", "news.quiboat.com",
"curiouscat.me", "www.occuworld.org", "www.yourlordthygod.com", "www.superinhuman.com",
"q-continuum.net", "https://socialscud.com/en", "www2.makebot.sh",
"www.socialnewsdesk.com", "www.echobox.com", "panel.socialpilot.co",
"leadstories.com", "www.powerapps.com", "www.tweetiumapp.com", "uk.reporte.us",
"www.socialjukebox.com", "www.ajaymatharu.com", "www.botize.com", "www.flipboard.com",
"www.tweetedtimes.com", "ingminds.com", "sakpol.se", "abraj.shahidvip.net",
"trueanthem.com", "janetter.net", "twittbot.net", "www.socialoomph.com",
"tweetlogix.com", "wezit.com", "pyraego.com", "twicca.r246.jp", "twibble.io",
"www.pwned.io", "www.samruston.co.uk", "xi.tv", "zou.tv", "www.AgendaOfEvil.com",
"pbump.com", "insubcontinent.com", "blog.christianebuddy.com", "www.asdf.com",
"www.zazoom.it", "www.titrespresse.com", "www.strictly-software.com",
"www.robinspost.com", "www.rightstreem.com", "www.myallies.com",
"www.informazione.it", "notiven.com", "www.rights.com", "drudgereportarchives.com",
"anonymo.us", "ctrlq.org", "KkimooKcomKkimooK.com", "f.tabtter.jp", "irna.ir",
"getfalcon.pro", "www.ucampaignapp.com", "www.iran-efshagari.com", "twblue.com.mx",
"www.thenewright.news", "todolist.x10.mx", "hamassenger.com", "megaph0ne.com",
"www.destroytwitter.com", "sinproject.net", "studio.twitter.com",
"www.dukascopy.com")
## Special look at:
# www.occuworld.org www.yourlordthygod.com www.superinhuman.com
# q-continuum.net www2.makebot.sh panel.socialpilot.co
# www.ajaymatharu.com ingminds.com sakpol.se abraj.shahidvip.net
# trueanthem.com janetter.net www.samruston.co.uk www.AgendaOfEvil.com
# pipes.cyberguerrilla.org www.rightstreem.com www.destroytwitter.com
# show URLs to check the source webpages
# unique(df$source[grepl("pipes.cyberguerrilla.org", df$source)])
# Tweets from these sources might be bots
botsAuto <- which(df[, grepl(paste(auto,collapse="|"), source)])
# Sometimes, bots use the same text, not marked as retweet.
botsDup <- which(duplicated(df$text)&df$retweet_count==0)
# bots post a lot (often). Take a look at distribution of
# tweets per user (logarithm to base 10)
hist(log10(df$statuses_count))
# Set time format to English
Sys.setlocale("LC_TIME", "C")
# Create column with age of accounts in days.
df$age <- sapply(df$user_created_at, function(x) Sys.Date() - as.Date(formatTwDate(x)))
# Divide number of tweets by days
df$TwPerDay <- df$statuses_count/df$age
# Take a look at the distribution
hist(log10(df$TwPerDay))
plot(df$TwPerDay)
# How many tweets per day is suspicious?
round(quantile(df$TwPerDay, probs= seq(0, 1, 0.05)))
# Take the upper five percent as Bots (without age 0)
hyp <- round(quantile(df$TwPerDay, probs= seq(0, 1, 0.05)))["95%"]
botsTWpD <- which(df$TwPerDay>hyp)
# Instead of taking the upper 5%, we could take 1.5 of InterQuartileRange,
# which is a classical outlier measurement.
IQR(df$TwPerDay)*1.5
# Friend/Follower ratio is important. Bots ratio is often around 1.
plot(df$favourites_count+1, df$friends_count+1, log = "xy")
abline(0,1)
# If FF-ratio is close to 1 and there are more than 100 followers
# it is likely a bot. Small number of followers could have FF-ratio
# close to 1, as well.
botsFF <- which(round((df$friends_count+1)/(df$followers_count+1),1)==1 &
df$followers_count>100)
# Combine all our bot-suspects.
# Any account, with any of the clues:
bots <- unique(c(botsDup, botsTWpD, botsFF, botsAuto))
# Only those accounts with at least two Bot-clues:
botsAnd <- c(botsDup,
botsTWpD,
botsFF,
botsAuto)[duplicated(c(botsDup,
botsTWpD,
botsFF,
botsAuto))]
# Media companies are using bots as well. But most of the times,
# they are verified users.
bots <- bots[-which(df$verified[bots]==T)]
botsAnd <- botsAnd[-which(df$verified[botsAnd]==T)]
Botsources <- URL_parts(df$source[bots])[,2]
sort(table(Botsources)[table(Botsources)>10], decreasing = T)
# Show 5 random bot texts.
df$text[bots][sample(length(bots), 5)]
# Get the 100 most active bots.
sort(table(df$screen_name[botsAnd]), decreasing = T)[1:100]
# Superb tutorial: http://www.rpubs.com/imtiazbdsrpubs/230283
# Build Wordcloud
#This function initialises the word_tokenizer which splits by spaces.
tok_fun = word_tokenizer # using word & not space tokenizers
#This function iterates over input objects
#This function creates iterators over input objects to vocabularies,
#corpora, or DTM and TCM matrices. This iterator is usually used in following functions :
#create_vocabulary, create_corpus, create_dtm, vectorizers, create_tcm
noBotTx <- df$text[-bots]
######
# as.vector(names(head(tsum, 100)))
stopw <- c("co", "https", "t", "the", "in", "of", "to", "a", "and", "is", "s",
"de", "are", "for", "on", "في","The", "that", "I", "amp","with",
"من", "have", "this", "you","it", "from", "en", "by", "This", "و",
"who", "be", "their", "as", "we", "da", "an", "la", "at", "all",
"they", "We", "was", "has", "no", "In", "will", "her", "don",
"than", "ve", "A", "iran", "İran", "about", "up", "over", "down",
"what", "i", "so", "but", "like", "would", "our", "They", "my", "can",
"2", "What", "off", "que", "them", "via", "1", "how", "You")
it_0 = itoken( noBotTx,
#preprocessor = text.clean,
tokenizer = tok_fun,
ids = rownames(df[-bots,]),
progressbar = T)
# func collects unique terms & corresponding statistics
#Creates a vocabulary of unique terms
vocab = create_vocabulary(it_0,
ngram = c(1L, 1L), #,
stopwords = stopw)
pruned_vocab = prune_vocabulary(vocab, # filters input vocab & throws out v frequent & v infrequent terms
doc_proportion_min = 0.001,
doc_proportion_max = 0.45)
# length(pruned_vocab); str(pruned_vocab)
vectorizer = vocab_vectorizer(pruned_vocab) # creates a text vectorizer func used in constructing a dtm/tcm/corpus
dtm_m = create_dtm(it_0, vectorizer) # high-level function for creating a document-term matrix
model_tfidf = TfIdf$new()
dtm.tfidf = model_tfidf$fit_transform(dtm_m)
tst = round(ncol(dtm.tfidf)/100)
a = rep(tst, 99)
b = cumsum(a);rm(a)
b = c(0,b,ncol(dtm.tfidf))
ss.col = c(NULL)
for (i in 1:(length(b)-1)) {
tempdtm = dtm.tfidf[,(b[i]+1):(b[i+1])]
s = colSums(as.matrix(tempdtm))
ss.col = c(ss.col,s)
}
tsum = ss.col
tsum = tsum[order(tsum, decreasing = T)] #terms in decreasing order of freq
head(tsum, 20)
## Bot Cloud
BotTx <- df$text[bots]
it_b = itoken( BotTx,
#preprocessor = text.clean,
tokenizer = tok_fun,
ids = rownames(df[bots,]),
progressbar = T)
# func collects unique terms & corresponding statistics
#Creates a vocabulary of unique terms
vocabB = create_vocabulary(it_b,
ngram = c(1L, 1L),
stopwords = stopw
)
pruned_vocabB = prune_vocabulary(vocabB, # filters input vocab & throws out v frequent & v infrequent terms
doc_proportion_min = 0.001,
doc_proportion_max = 0.45)
# length(pruned_vocab); str(pruned_vocab)
vectorizerB = vocab_vectorizer(pruned_vocabB) # creates a text vectorizer func used in constructing a dtm/tcm/corpus
dtm_b = create_dtm(it_b, vectorizerB) # high-level function for creating a document-term matrix
model_tfidfB = TfIdf$new()
dtm_b.tfidf = model_tfidfB$fit_transform(dtm_b)
tst = round(ncol(dtm_b.tfidf)/100)
a = rep(tst, 99)
b = cumsum(a);rm(a)
b = c(0,b,ncol(dtm_b.tfidf))
ss.col = c(NULL)
for (i in 1:(length(b)-1)) {
tempdtm = dtm_b.tfidf[,(b[i]+1):(b[i+1])]
s = colSums(as.matrix(tempdtm))
ss.col = c(ss.col,s)
}
tsumB = ss.col
tsumB = tsumB[order(tsumB, decreasing = T)] #terms in decreasing order of freq
head(tsumB)
BotATx <- df$text[botsAnd]
it_ba = itoken( BotATx,
#preprocessor = text.clean,
tokenizer = tok_fun,
ids = rownames(df[botsAnd,]),
progressbar = T)
# func collects unique terms & corresponding statistics
#Creates a vocabulary of unique terms
vocabBa = create_vocabulary(it_ba,
ngram = c(1L, 1L),
stopwords = stopw
)
pruned_vocabBa = prune_vocabulary(vocabBa, # filters input vocab & throws out v frequent & v infrequent terms
doc_proportion_min = 0.001,
doc_proportion_max = 0.45)
# length(pruned_vocab); str(pruned_vocab)
vectorizerBa = vocab_vectorizer(pruned_vocabBa) # creates a text vectorizer func used in constructing a dtm/tcm/corpus
dtm_ba = create_dtm(it_ba, vectorizerBa) # high-level function for creating a document-term matrix
model_tfidfBa = TfIdf$new()
dtm_ba.tfidf = model_tfidfBa$fit_transform(dtm_ba)
tst = round(ncol(dtm_ba.tfidf)/100)
a = rep(tst, 99)
b = cumsum(a);rm(a)
b = c(0,b,ncol(dtm_ba.tfidf))
ss.col = c(NULL)
for (i in 1:(length(b)-1)) {
tempdtm = dtm_ba.tfidf[,(b[i]+1):(b[i+1])]
s = colSums(as.matrix(tempdtm))
ss.col = c(ss.col,s)
}
tsumBa = ss.col
tsumBa = tsumBa[order(tsumBa, decreasing = T)] #terms in decreasing order of freq
head(tsumBa)
png("NoBotsCloud.png", type = "cairo", units = "cm", width = 30, height = 15, res = 600)
par(mfrow=c(1,3))
wordcloud(names(tsum), tsum, scale=c(2,0.5),0.05,
max.words=300, random.order=FALSE, rot.per=0.35,
colors=colorRampPalette(c("orange", "black"))(100), random.color = T) # Plot results in a word cloud
title(sub = "NoBots")
wordcloud(names(tsumB), tsumB, scale=c(2,0.5),0.05,
max.words=300, random.order=FALSE, rot.per=0.35,
colors=colorRampPalette(c("lightblue", "black"))(100), random.color = T) # Plot results in a word cloud
title(sub = "Suspicious")
wordcloud(names(tsumBa), tsumBa, scale=c(2,0.5),0.05,
max.words=300, random.order=FALSE, rot.per=0.35,
colors=colorRampPalette(c("red", "black"))(100), random.color = T) # Plot results in a word cloud
title(sub = "Bots")
dev.off()
# plot barchart for top tokens
png("WordList.png", type = "cairo", units = "cm", width = 30, height = 15, res = 600)
test = as.data.frame(round(tsum[1:40],0))
# New plot window
p1 <- ggplot(test, aes(x = rownames(test), y = test)) +
geom_bar(stat = "identity", fill = "orange") +
geom_text(aes(label = test), vjust= -0.20) +
coord_flip() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
# Term co-occurence matrix and co-occurence graphs
testB = as.data.frame(round(tsumB[1:40],0))
# New plot window
p2 <- ggplot(testB, aes(x = rownames(testB), y = testB)) +
geom_bar(stat = "identity", fill = "blue") +
geom_text(aes(label = test), vjust= -0.20) +
coord_flip() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
testBa = as.data.frame(round(tsumBa[1:40],0))
# New plot window
p3 <- ggplot(testBa, aes(x = rownames(testBa), y = testBa)) +
geom_bar(stat = "identity", fill = "red") +
geom_text(aes(label = test), vjust= -0.20) +
coord_flip() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
multiplot(p1, p2, p3,cols=3)
dev.off()
# Term co-occurence matrix and co-occurence graphs
vectorizerB = vocab_vectorizer(pruned_vocabB)
tcmB = create_tcm(it_b, vectorizerB,skip_grams_window = 5L) # func to build a TCM
tcm.matB = as.matrix(tcmB) # use tcm.mat[1:5, 1:5] to view
vectorizerBa = vocab_vectorizer(pruned_vocabBa)
tcmBa = create_tcm(it_ba, vectorizerBa,skip_grams_window = 5L) # func to build a TCM
tcm.matBa = as.matrix(tcmBa)
vectorizer = vocab_vectorizer(pruned_vocab)
tcm = create_tcm(it_0, vectorizer,skip_grams_window = 5L) # func to build a TCM
tcm.mat = as.matrix(tcm)
## adj.mat and distilled cog for tfidf DTMs ##
adj.mat = t(dtm.tfidf) %*% dtm.tfidf
diag(adj.mat) = 0
a0 = order(apply(adj.mat, 2, sum), decreasing = T)
adj.mat = as.matrix(adj.mat[a0[1:300], a0[1:300]])
adj.matB = t(dtm_b.tfidf) %*% dtm_b.tfidf
diag(adj.matB) = 0
a0 = order(apply(adj.matB, 2, sum), decreasing = T)
adj.matB = as.matrix(adj.matB[a0[1:300], a0[1:300]])
adj.matBa = t(dtm_ba.tfidf) %*% dtm_ba.tfidf
diag(adj.matBa) = 0
a0 = order(apply(adj.matBa, 2, sum), decreasing = T)
adj.matBa = as.matrix(adj.matBa[a0[1:300], a0[1:300]])
png("COGNo.png", type = "cairo", units = "cm", width = 20, height = 20, res = 600,
pointsize = 9)
distill.cog(adj.mat, 'COG-tfidf NoBots', 20, 5, c("green", "orange"))
dev.off()
png("COGSus.png", type = "cairo", units = "cm", width = 20, height = 20, res = 600,
pointsize = 9)
distill.cog(adj.matB, 'COG-tfidf Sucpicious', 20, 5, c("green", "lightblue"))
dev.off()
png("COGBot.png", type = "cairo", units = "cm", width = 20, height = 20, res = 600,
pointsize = 9)
distill.cog(adj.matB, 'COG-tfidf Bots', 20, 5, c("green", "red"))
dev.off()
t1 = Sys.time() # set timer
pol = polarity(text.clean(df$text[-bots]) ) # Calculate the polarity from qdap dictionary
Sys.time() - t1 # how much time did the above take?
head(pol$all)
pol$group$ave.polarity
polBots <- polarity(text.clean(df$text[bots]) )
polBots$group$ave.polarity
polBotsA <- polarity(text.clean(df$text[botsAnd]) )
polBotsA$group$ave.polarity
ks.test(polBots$all$polarity, pol$all$polarity)
ks.test(polBotsA$all$polarity, pol$all$polarity)
png("ECDF.png", type = "cairo", units = "cm", width = 21, height = 13, res = 600,
pointsize = 11)
plot(ecdf(x = pol$all$polarity),
verticals = TRUE,
do.points = FALSE,
main = "ECDF",
xlab="Polarity", ylab=" ",
col= "orange")
lines(ecdf(x = polBots$all$polarity), col = "lightblue", verticals = TRUE, do.points = FALSE)
lines(ecdf(x = polBotsA$all$polarity), col = "red", verticals = TRUE, do.points = FALSE)
legend("topleft", c("NoBots", "Suspicious", "Bots"),
fill = c("orange", "lightblue", "red"))
dev.off()
library(tm)
library(SnowballC)
library(wordcloud)
library(RColorBrewer)
library(text2vec)
library(stringr)
library(RWeka)
library(tokenizers)
library(slam)
library(ggplot2)
library(igraph)
library(textir)
library(qdap)
df <- readRDS("iranDF.rds")
setDT(df)
class(df)
sources <- df[, URL_parts(source)[,2]]
sort(table(sources)[table(sources)>10], decreasing = T)
# Sources other than twitter.com are suspicious
#collect suspicious sources
auto <- c("publicize.wp.com", "www.echofon.com", "www.hootsuite.com", "tapbots.com",
"www.tweetcaster.com", "www.crowdfireapp.com", "ifttt.com", "twittbot.net", "software.complete.org",
"twicca.r246.jp", "roundteam.co", "twibble.io", "paper.li", "twitterrific.com", "mvilla.it",
"dlvrit.com", "bufferapp.com", "www.lost-property.eu", "www.newsdingo.com",
"www.news365247live.com", "corebird.baedert.org", "earthobservatory.ch",
"www.besoyepirozi.com","nosudo.co", "www.twitpane.com", "www.twhirl.org",
"www.handmark.com", "www.bennedemisim.com", "trendinalia.com", "news.quiboat.com",
"curiouscat.me", "www.occuworld.org", "www.yourlordthygod.com", "www.superinhuman.com",
"q-continuum.net", "https://socialscud.com/en", "www2.makebot.sh",
"www.socialnewsdesk.com", "www.echobox.com", "panel.socialpilot.co",
"leadstories.com", "www.powerapps.com", "www.tweetiumapp.com", "uk.reporte.us",
"www.socialjukebox.com", "www.ajaymatharu.com", "www.botize.com", "www.flipboard.com",
"www.tweetedtimes.com", "ingminds.com", "sakpol.se", "abraj.shahidvip.net",
"trueanthem.com", "janetter.net", "twittbot.net", "www.socialoomph.com",
"tweetlogix.com", "wezit.com", "pyraego.com", "twicca.r246.jp", "twibble.io",
"www.pwned.io", "www.samruston.co.uk", "xi.tv", "zou.tv", "www.AgendaOfEvil.com",
"pbump.com", "insubcontinent.com", "blog.christianebuddy.com", "www.asdf.com",
"www.zazoom.it", "www.titrespresse.com", "www.strictly-software.com",
"www.robinspost.com", "www.rightstreem.com", "www.myallies.com",
"www.informazione.it", "notiven.com", "www.rights.com", "drudgereportarchives.com",
"anonymo.us", "ctrlq.org", "KkimooKcomKkimooK.com", "f.tabtter.jp", "irna.ir",
"getfalcon.pro", "www.ucampaignapp.com", "www.iran-efshagari.com", "twblue.com.mx",
"www.thenewright.news", "todolist.x10.mx", "hamassenger.com", "megaph0ne.com",
"www.destroytwitter.com", "sinproject.net", "studio.twitter.com",
"www.dukascopy.com")
## Special look at:
# www.occuworld.org www.yourlordthygod.com www.superinhuman.com
# q-continuum.net www2.makebot.sh panel.socialpilot.co
# www.ajaymatharu.com ingminds.com sakpol.se abraj.shahidvip.net
# trueanthem.com janetter.net www.samruston.co.uk www.AgendaOfEvil.com
# pipes.cyberguerrilla.org www.rightstreem.com www.destroytwitter.com
# show URLs to check the source webpages
# unique(df$source[grepl("pipes.cyberguerrilla.org", df$source)])
# Tweets from these sources might be bots
botsAuto <- which(df[, grepl(paste(auto,collapse="|"), source)])
# Sometimes, bots use the same text, not marked as retweet.
botsDup <- which(duplicated(df$text)&df$retweet_count==0)
# bots post a lot (often). Take a look at distribution of
# tweets per user (logarithm to base 10)
hist(log10(df$statuses_count))
# Set time format to English
Sys.setlocale("LC_TIME", "C")
# Create column with age of accounts in days.
df$age <- sapply(df$user_created_at, function(x) Sys.Date() - as.Date(formatTwDate(x)))
# Divide number of tweets by days
df$TwPerDay <- df$statuses_count/df$age
# Take a look at the distribution
hist(log10(df$TwPerDay))
plot(df$TwPerDay)
# How many tweets per day is suspicious?
round(quantile(df$TwPerDay, probs= seq(0, 1, 0.05)))
# Take the upper five percent as Bots (without age 0)
hyp <- round(quantile(df$TwPerDay, probs= seq(0, 1, 0.05)))["95%"]
botsTWpD <- which(df$TwPerDay>hyp)
# Instead of taking the upper 5%, we could take 1.5 of InterQuartileRange,
# which is a classical outlier measurement.
IQR(df$TwPerDay)*1.5
# Friend/Follower ratio is important. Bots ratio is often around 1.
plot(df$favourites_count+1, df$friends_count+1, log = "xy")
abline(0,1)
# If FF-ratio is close to 1 and there are more than 100 followers
# it is likely a bot. Small number of followers could have FF-ratio
# close to 1, as well.
botsFF <- which(round((df$friends_count+1)/(df$followers_count+1),1)==1 &
df$followers_count>100)
# Combine all our bot-suspects.
# Any account, with any of the clues:
bots <- unique(c(botsDup, botsTWpD, botsFF, botsAuto))
# Only those accounts with at least two Bot-clues:
botsAnd <- c(botsDup,
botsTWpD,
botsFF,
botsAuto)[duplicated(c(botsDup,
botsTWpD,
botsFF,
botsAuto))]
# Media companies are using bots as well. But most of the times,
# they are verified users.
bots <- bots[-which(df$verified[bots]==T)]
botsAnd <- botsAnd[-which(df$verified[botsAnd]==T)]
Botsources <- URL_parts(df$source[bots])[,2]
sort(table(Botsources)[table(Botsources)>10], decreasing = T)
# Show 5 random bot texts.
df$text[bots][sample(length(bots), 5)]
# Get the 100 most active bots.
sort(table(df$screen_name[botsAnd]), decreasing = T)[1:100]
# Superb tutorial: http://www.rpubs.com/imtiazbdsrpubs/230283
# Build Wordcloud
#This function initialises the word_tokenizer which splits by spaces.
tok_fun = word_tokenizer # using word & not space tokenizers
#This function iterates over input objects
#This function creates iterators over input objects to vocabularies,
#corpora, or DTM and TCM matrices. This iterator is usually used in following functions :
#create_vocabulary, create_corpus, create_dtm, vectorizers, create_tcm
noBotTx <- df$text[-bots]
######
# as.vector(names(head(tsum, 100)))
stopw <- c("co", "https", "t", "the", "in", "of", "to", "a", "and", "is", "s",
"de", "are", "for", "on", "في","The", "that", "I", "amp","with",
"من", "have", "this", "you","it", "from", "en", "by", "This", "و",
"who", "be", "their", "as", "we", "da", "an", "la", "at", "all",
"they", "We", "was", "has", "no", "In", "will", "her", "don",
"than", "ve", "A", "iran", "İran", "about", "up", "over", "down",
"what", "i", "so", "but", "like", "would", "our", "They", "my", "can",
"2", "What", "off", "que", "them", "via", "1", "how", "You")
it_0 = itoken( noBotTx,
#preprocessor = text.clean,
tokenizer = tok_fun,
ids = rownames(df[-bots,]),
progressbar = T)
# func collects unique terms & corresponding statistics
#Creates a vocabulary of unique terms
vocab = create_vocabulary(it_0,
ngram = c(1L, 1L), #,
stopwords = stopw)
pruned_vocab = prune_vocabulary(vocab, # filters input vocab & throws out v frequent & v infrequent terms
doc_proportion_min = 0.001,
doc_proportion_max = 0.45)
# length(pruned_vocab); str(pruned_vocab)
vectorizer = vocab_vectorizer(pruned_vocab) # creates a text vectorizer func used in constructing a dtm/tcm/corpus
dtm_m = create_dtm(it_0, vectorizer) # high-level function for creating a document-term matrix
model_tfidf = TfIdf$new()
dtm.tfidf = model_tfidf$fit_transform(dtm_m)
tst = round(ncol(dtm.tfidf)/100)
a = rep(tst, 99)
b = cumsum(a);rm(a)
b = c(0,b,ncol(dtm.tfidf))
ss.col = c(NULL)
for (i in 1:(length(b)-1)) {
tempdtm = dtm.tfidf[,(b[i]+1):(b[i+1])]
s = colSums(as.matrix(tempdtm))
ss.col = c(ss.col,s)
}
tsum = ss.col
tsum = tsum[order(tsum, decreasing = T)] #terms in decreasing order of freq
head(tsum, 20)
## Bot Cloud
BotTx <- df$text[bots]
it_b = itoken( BotTx,
#preprocessor = text.clean,
tokenizer = tok_fun,
ids = rownames(df[bots,]),
progressbar = T)
# func collects unique terms & corresponding statistics
#Creates a vocabulary of unique terms
vocabB = create_vocabulary(it_b,
ngram = c(1L, 1L),
stopwords = stopw
)
pruned_vocabB = prune_vocabulary(vocabB, # filters input vocab & throws out v frequent & v infrequent terms
doc_proportion_min = 0.001,
doc_proportion_max = 0.45)
# length(pruned_vocab); str(pruned_vocab)
vectorizerB = vocab_vectorizer(pruned_vocabB) # creates a text vectorizer func used in constructing a dtm/tcm/corpus
dtm_b = create_dtm(it_b, vectorizerB) # high-level function for creating a document-term matrix
model_tfidfB = TfIdf$new()
dtm_b.tfidf = model_tfidfB$fit_transform(dtm_b)
tst = round(ncol(dtm_b.tfidf)/100)
a = rep(tst, 99)
b = cumsum(a);rm(a)
b = c(0,b,ncol(dtm_b.tfidf))
ss.col = c(NULL)
for (i in 1:(length(b)-1)) {
tempdtm = dtm_b.tfidf[,(b[i]+1):(b[i+1])]
s = colSums(as.matrix(tempdtm))
ss.col = c(ss.col,s)
}
tsumB = ss.col
tsumB = tsumB[order(tsumB, decreasing = T)] #terms in decreasing order of freq
head(tsumB)
BotATx <- df$text[botsAnd]
it_ba = itoken( BotATx,
#preprocessor = text.clean,
tokenizer = tok_fun,
ids = rownames(df[botsAnd,]),
progressbar = T)
# func collects unique terms & corresponding statistics
#Creates a vocabulary of unique terms
vocabBa = create_vocabulary(it_ba,
ngram = c(1L, 1L),
stopwords = stopw
)
pruned_vocabBa = prune_vocabulary(vocabBa, # filters input vocab & throws out v frequent & v infrequent terms
doc_proportion_min = 0.001,
doc_proportion_max = 0.45)
# length(pruned_vocab); str(pruned_vocab)
vectorizerBa = vocab_vectorizer(pruned_vocabBa) # creates a text vectorizer func used in constructing a dtm/tcm/corpus
dtm_ba = create_dtm(it_ba, vectorizerBa) # high-level function for creating a document-term matrix
model_tfidfBa = TfIdf$new()
dtm_ba.tfidf = model_tfidfBa$fit_transform(dtm_ba)
tst = round(ncol(dtm_ba.tfidf)/100)
a = rep(tst, 99)
b = cumsum(a);rm(a)
b = c(0,b,ncol(dtm_ba.tfidf))
ss.col = c(NULL)
for (i in 1:(length(b)-1)) {
tempdtm = dtm_ba.tfidf[,(b[i]+1):(b[i+1])]
s = colSums(as.matrix(tempdtm))
ss.col = c(ss.col,s)
}
tsumBa = ss.col
tsumBa = tsumBa[order(tsumBa, decreasing = T)] #terms in decreasing order of freq
head(tsumBa)
png("NoBotsCloud.png", type = "cairo", units = "cm", width = 30, height = 15, res = 600)
par(mfrow=c(1,3))
wordcloud(names(tsum), tsum, scale=c(2,0.5),0.05,
max.words=300, random.order=FALSE, rot.per=0.35,
colors=colorRampPalette(c("orange", "black"))(100), random.color = T) # Plot results in a word cloud
title(sub = "NoBots")
wordcloud(names(tsumB), tsumB, scale=c(2,0.5),0.05,
max.words=300, random.order=FALSE, rot.per=0.35,
colors=colorRampPalette(c("lightblue", "black"))(100), random.color = T) # Plot results in a word cloud
title(sub = "Suspicious")
wordcloud(names(tsumBa), tsumBa, scale=c(2,0.5),0.05,
max.words=300, random.order=FALSE, rot.per=0.35,
colors=colorRampPalette(c("red", "black"))(100), random.color = T) # Plot results in a word cloud
title(sub = "Bots")
dev.off()
# plot barchart for top tokens
png("WordList.png", type = "cairo", units = "cm", width = 30, height = 15, res = 600)
test = as.data.frame(round(tsum[1:40],0))
# New plot window
p1 <- ggplot(test, aes(x = rownames(test), y = test)) +
geom_bar(stat = "identity", fill = "orange") +
geom_text(aes(label = test), vjust= -0.20) +
coord_flip() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
# Term co-occurence matrix and co-occurence graphs
testB = as.data.frame(round(tsumB[1:40],0))
# New plot window
p2 <- ggplot(testB, aes(x = rownames(testB), y = testB)) +
geom_bar(stat = "identity", fill = "blue") +
geom_text(aes(label = test), vjust= -0.20) +
coord_flip() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
testBa = as.data.frame(round(tsumBa[1:40],0))
# New plot window
p3 <- ggplot(testBa, aes(x = rownames(testBa), y = testBa)) +
geom_bar(stat = "identity", fill = "red") +
geom_text(aes(label = test), vjust= -0.20) +
coord_flip() +
theme(axis.text.x = element_text(angle = 90, hjust = 1))
multiplot(p1, p2, p3,cols=3)
dev.off()
# Term co-occurence matrix and co-occurence graphs
vectorizerB = vocab_vectorizer(pruned_vocabB)
tcmB = create_tcm(it_b, vectorizerB,skip_grams_window = 5L) # func to build a TCM
tcm.matB = as.matrix(tcmB) # use tcm.mat[1:5, 1:5] to view
vectorizerBa = vocab_vectorizer(pruned_vocabBa)
tcmBa = create_tcm(it_ba, vectorizerBa,skip_grams_window = 5L) # func to build a TCM
tcm.matBa = as.matrix(tcmBa)
vectorizer = vocab_vectorizer(pruned_vocab)
tcm = create_tcm(it_0, vectorizer,skip_grams_window = 5L) # func to build a TCM
tcm.mat = as.matrix(tcm)
## adj.mat and distilled cog for tfidf DTMs ##
adj.mat = t(dtm.tfidf) %*% dtm.tfidf
diag(adj.mat) = 0
a0 = order(apply(adj.mat, 2, sum), decreasing = T)
adj.mat = as.matrix(adj.mat[a0[1:300], a0[1:300]])
adj.matB = t(dtm_b.tfidf) %*% dtm_b.tfidf
diag(adj.matB) = 0
a0 = order(apply(adj.matB, 2, sum), decreasing = T)
adj.matB = as.matrix(adj.matB[a0[1:300], a0[1:300]])
adj.matBa = t(dtm_ba.tfidf) %*% dtm_ba.tfidf
diag(adj.matBa) = 0
a0 = order(apply(adj.matBa, 2, sum), decreasing = T)
adj.matBa = as.matrix(adj.matBa[a0[1:300], a0[1:300]])
png("COGNo.png", type = "cairo", units = "cm", width = 20, height = 20, res = 600,
pointsize = 9)
distill.cog(adj.mat, 'COG-tfidf NoBots', 20, 5, c("green", "orange"))
dev.off()
png("COGSus.png", type = "cairo", units = "cm", width = 20, height = 20, res = 600,
pointsize = 9)
distill.cog(adj.matB, 'COG-tfidf Sucpicious', 20, 5, c("green", "lightblue"))
dev.off()
png("COGBot.png", type = "cairo", units = "cm", width = 20, height = 20, res = 600,
pointsize = 9)
distill.cog(adj.matB, 'COG-tfidf Bots', 20, 5, c("green", "red"))
dev.off()
t1 = Sys.time() # set timer
pol = polarity(text.clean(df$text[-bots]) ) # Calculate the polarity from qdap dictionary
Sys.time() - t1 # how much time did the above take?
head(pol$all)
pol$group$ave.polarity
polBots <- polarity(text.clean(df$text[bots]) )
polBots$group$ave.polarity
polBotsA <- polarity(text.clean(df$text[botsAnd]) )
polBotsA$group$ave.polarity
ks.test(polBots$all$polarity, pol$all$polarity)
ks.test(polBotsA$all$polarity, pol$all$polarity)
png("ECDF.png", type = "cairo", units = "cm", width = 21, height = 13, res = 600,
pointsize = 11)
plot(ecdf(x = pol$all$polarity),
verticals = TRUE,
do.points = FALSE,
main = "ECDF",
xlab="Polarity", ylab=" ",
col= "orange")
lines(ecdf(x = polBots$all$polarity), col = "lightblue", verticals = TRUE, do.points = FALSE)
lines(ecdf(x = polBotsA$all$polarity), col = "red", verticals = TRUE, do.points = FALSE)
legend("topleft", c("NoBots", "Suspicious", "Bots"),
fill = c("orange", "lightblue", "red"))
dev.off()